目录
- 一、数据生成机制对比:多球组合随机抽取 vs 三数求和
- 二、概率分布特征:乐透彩票的均等概率 vs PC28的钟形分布
- 三、开奖频率与历史数据积累速度的差异
- 四、如何利用不同的数据模型分析这两类截然不同的彩票数据
一、数据生成机制对比:多球组合随机抽取 vs 三数求和
在概率学与数理统计的研究中,不同类型彩票的数据生成机制决定了其底层数据结构的本质差异。传统乐透型彩票(如双色球、大乐透等)通常采用“多球组合、无放回随机抽取”的机制。例如,从33个红球中随机抽取6个,再从16个蓝球中抽取1个。这种机制下,每一个号码组合的出现都是一个独立的、平权的高维空间事件。
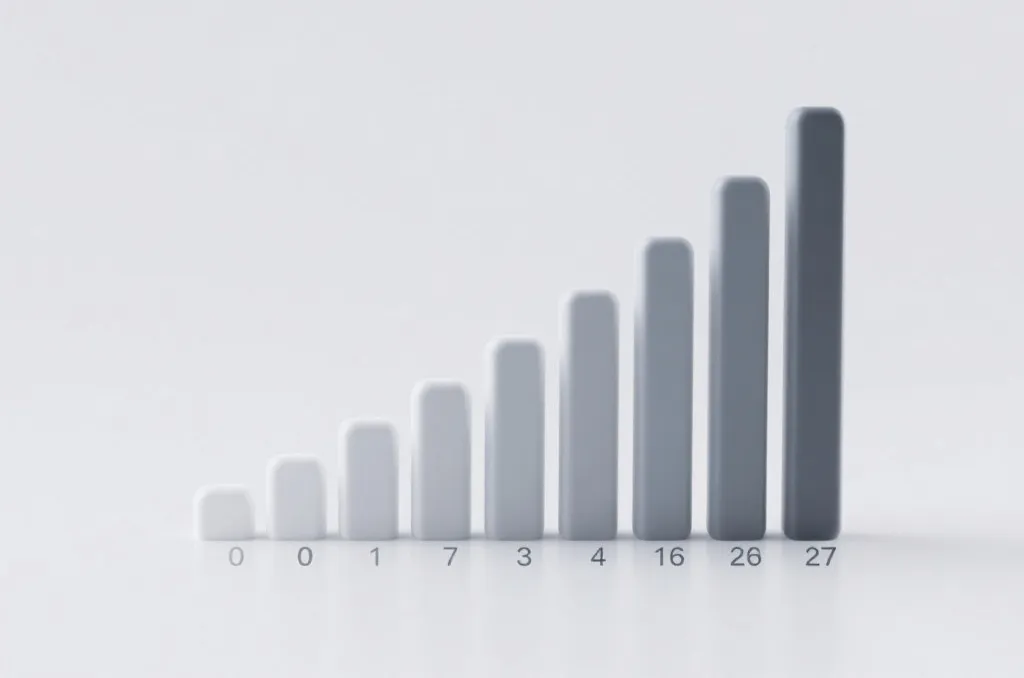
相比之下,加拿大PC28的数据生成机制则属于“三数求和”模型。在加拿大PC28开奖算法揭秘中,我们知道其开奖结果是由三个独立随机产生的个位数(0-9)相加得到的,最终的和值范围在0-27之间。由于引入了“求和”这一数学运算,原本均匀分布的独立随机变量在叠加后,其数据结构发生了根本性的变化。这使得PC28不再是单纯的等概率选择,而是呈现出极强的统计学规律。
二、概率分布特征:乐透彩票的均等概率 vs PC28的钟形分布
传统乐透型彩票的每一个单号在单次抽取中,被抽中的概率是完全均等的。例如,在1至33个号码中,号码1和号码18在任意一次摇奖中出现的概率没有任何区别,均遵循离散均匀分布。任何关于“热号”或“冷号”的短期现象,在长期来看都会严格回归到均等概率线上。
然而,加拿大PC28的和值概率分布则完全不同。由于其结果是三个0-9的独立随机数之和,其概率分布呈现出经典的“钟形分布”(类似于离散的正态分布)。
| 和值类型 | 可能组合数 | 理论概率 | 分布特征 |
|---|---|---|---|
| 极值(如 0 或 27) | 1 种 | 约 0.1% | 极低频区(两端) |
| 中值(如 13 或 14) | 75 种 | 约 7.5% | 高频区(中心) |
| 均匀单号(传统乐透) | 1 种 | 完全均等 | 无起伏线性分布 |
从上表可以看出,由于组合数差异巨大,中间数值(13、14)出现的概率是两端极值(0、27)的75倍。这种非均等的概率结构,使得PC28的数据分析天然具备了统计学上的“均值回归”属性,即数值在偏离中心区域后,有极大概率向中间值靠拢。
三、开奖频率与历史数据积累速度的差异
除了底层数学模型不同,两者的开奖频率和数据积累速度也存在着量级上的差异。传统乐透型彩票通常为每日一期或每周数期,历史数据的积累速度较为缓慢。对于研究者而言,可能需要收集数年甚至数十年的开奖记录,才能获得几千组样本数据,这在统计学上容易受到“小样本偏差”的干扰。
相反,加拿大PC28具有极高的开奖频率。在极短的周期内,平台就会产生大量的实时开奖数据。这种高频特性使得数据研究者能够在极短时间内获取数万期、甚至数十万期的海量样本。充足的样本量为验证大数定律、进行深度的数据回测提供了完美的温床。如果你想了解如何利用这些高频数据,可以参考如何高效利用加拿大PC28历史记录进行周期性趋势分析?。

四、如何利用不同的数据模型分析这两类截然不同的彩票数据
由于数据结构与概率分布的本质不同,研究者在面对这两类彩票时,必须采用完全不同的数学模型:
- 传统乐透彩票分析模型:主要依赖于组合数学与图论。分析的核心在于大样本下号码组合的覆盖率、奇偶比、区间分布等,由于单号概率均等,任何预测模型都必须建立在承认“每一次开奖都是绝对独立且概率均等”的前提下。
- PC28求和型数据分析模型:主要依赖于概率论中的中心极限定理与均值回归理论。分析者可以通过跟踪当前和值偏离平均值(13.5)的标准差,来评估短期内数据回归常态的概率。通过对历史和值波动的标准差分析,可以更科学地识别出数据的异常波动周期,从而规避盲目跟风的误区。
总结来说,传统乐透彩票是均等概率下的多维组合博弈,而加拿大PC28则是钟形分布下的和值回归分析。理解这两者在数据结构上的本质区别,是彩票数据研究者和统计学爱好者迈向理性分析的关键一步。